
버블 정렬 (Bubble sort)
- 두 인접한 데이터의 크기를 비교해 정렬하는 방법
- 루프를 돌면서 인접한 데이터 간의 swap 연산으로 정렬한다
- 간단하게 구현이 가능하다
- 시간 복잡도 O(n^2) → 다른 정렬 알고리즘에 비해 속도가 느리다
- 루프 1번 돌 때마다 하나씩 fix(정렬)되는것
- 루프 1번 돌 때 n번 탐색 * 루프 n번 실행 ⇒ O(n^2)
버블 정렬 과정
- 비교 연산이 필요한 루프 범위를 설정한다
- 인접한 데이터 값을 비교한다
- swap 조건에 부합하면 swap 연산을 수행한다
- 루프 범위가 끝날 때까지 (2)~(3)을 반복한다
- 정렬 영역을 설정하고, 다음 루프를 실행할 때는 이 영역을 제외한다
- 비교 대상이 없을 때까지 (1)~(5)를 반복한다
만약 특정한 루프의 전체 영역에서 swap이 한번도 발생하지 않았다면 그 영역 뒤에 있는 데이터가 모두 정렬됐다는 뜻이므로 프로세스를 종료해도 된다
선택 정렬 (Selection sort)
- 대상 데이터에서 최대나 최소 데이터를 데이터가 나열된 순으로 찾아가며 선택하는 방법
- 구현 방법이 복잡하다
- 시간복잡도도 O(n^2)으로 효율적이지 않아 코딩테스트에서 많이 사용하지 않는다
- min 또는 Max값을 찾고, 남은 정렬 부분의 가장 앞에 있는 데이터와 swap하는 것이 핵심
선택 정렬 과정
- 남은 정렬 부분에서 최솟값 또는 최댓값을 찾는다
- 남은 정렬 부분에서 가장 앞에 있는 데이터와 선택된 데이터를 swap한다
- 가장 앞에 있는 데이터의 위치를 변경해(index++) 남은 정렬 부분의 범위를 축소한다
- 전체 데이터 크기만큼 index가 커질 때까지, 즉 남은 정렬 부분이 없을 때까지 반복한다
선택 정렬 시간복잡도 구하기
- 최솟값 찾기 위해 N만큼 탐색 → 1개 정렬 완료
- 정렬된 것 제외 N-1만큼 탐색
- 정렬된 것 제외 N-2만큼 탐색
위 과정 N번 반복
⇒ O(N^2)
삽입 정렬 (Insertion Sort)
- 이미 정렬된 데이터 범위에 정렬되지 않은 데이터를 적절한 위치에 삽입시켜 정렬하는 방식
- 시간복잡도는 O(n^2)으로 느린 편이지만 구현이 쉽다
- 선택 데이터를 현재 정렬된 데이터 범위 내에서 적절한 위치에 삽입하는 것이 핵심
삽입 정렬 과정
- 현재 index에 있는 데이터 값을 선택한다
- 현재 선택한 데이터가 정렬된 데이터 범위에 삽입될 위치를 탐색한다
- 삽입 위치부터 index에 있는 위치까지 shift 연산을 수행한다
- 삽입 위치에 현재 선택한 데이터를 삽입하고 index++연산을 수행한다
- 전체 데이터의 크기만큼 index가 커질 때까지, 즉 선택할 데이터가 없을 때까지 반복한다
적절한 삽입 위치를 탐색하는 부분에서 이진 탐색 등과 같은 탐색 알고리즘을 사용하면 시간 복잡도를 줄일 수 있다
- 이진 탐색으로 O(N) -> O(logN)으로 줄일 수 있다
- 하지만 shift연산을 수행할 때 시간이 많이 소요된다
퀵 정렬 (Quick Sort)
- 기준값(pivot)을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘
- 기준값이 어떻게 선정되는지가 시간복잡도에 많은 영향을 미친다
- 평균 시간복잡도 : O(nlogn)
- 최악 시간복잡도 : O(n^2)
- 기준값이 어떻게 선정되는지가 시간복잡도에 많은 영향을 미친다
 |
|
- pivot을 중심으로 계속 데이터를 2개의 집합으로 나누면서 정렬하는 것이 퀵 정렬의 핵심
퀵 정렬 과정
- 데이터를 분할하는 pivot을 설정한다
- pivot을 기준으로 다음 a~e의 과정을 거쳐 데이터를 2개의 집합으로 분리한다
- (a) start가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start를 오른쪽으로 1칸 이동한다
- (b) end가 가리키는 데이터가 pivot이 가리키는 데이터보다 크면 end를 왼쪽으로 1칸 이동한다
- (c) start가 가리키는 데이터가 pivot이 가리키는 데이터보다 크고, end가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start, end가 가리키는 데이터를 swap하고 start는 오른쪽, end는 왼쪽으로 1칸씩 이동한다
- (d) start와 end가 만날 때까지 (a)~(c)를 반복한다
- (e) start와 end가 만나면 만난 지점에서 가리키는 데이터와 pivot이 가리키는 데이터를 비교하여 pivot이 가리키는 데이터가 크면 만난 지점의 오른쪽에, 작으면 만난 지점의 왼쪽에 pivot이 가리키는 데이터를 삽입한다
- 분리 집합에서 각각 다시 pivot을 선정한다
- 분리 집합이 1개 이하가 될 때까지 과정 (1)~(3)을 반복한다
병합 정렬 (Merge Sort)
- 분할 정복(divide and conquer) 방식을 사용해 데이터를 분할하고 분할한 집합을 정렬하며 합치는 알고리즘
- 시간 복잡도 : O(nlogn)
- n번의 data access가 있음(투 포인터로 각 그룹을 탐색하므로)& 그 과정을 ${log}_2{n}$만큼 수행(2개씩 병합하니까)
- ex) 8개의 원소 → 8 * log(2)8 = 24
병합 정렬 과정
 |
|
병합 정렬은 코딩테스트의 정렬 관련 문제에서 자주 등장한다. 특히 2개의 그룹을 병합하는 원리를 꼭 숙지해야 한다!
2개의 그룹을 병합하는 과정

- 투 포인터 개념을 사용하여 왼쪽, 오른쪽 그룹을 병합한다
- 왼쪽 포인터와 오른쪽 포인터의 값을 비교하여 작은 값을 결과 배열에 추가하고 포인터를 오른쪽으로 1칸 이동시킨다
- 한쪽 그룹의 모든 숫자가 결과 배열에 추가되었을 경우, 다른 배열의 남은 숫자를 그대로 결과 배열 뒤쪽에 넣어준다
- 이 예제를 버블소트로 해결하려면 swap이 무려 9번이나 일어나게 된다
기수 정렬 (Radix Sort)
- 값을 비교하지 않는 특이한 정렬
- 값을 놓고 비교할 자릿수를 정한 다음 해당 자릿수만 비교한다
- 시간 복잡도 : O(kn)
- k : 데이터의 자릿수
기수 정렬 과정
- 기수 정렬은 10개의 큐를 이용하며, 각 큐는 값의 자릿수를 대표한다
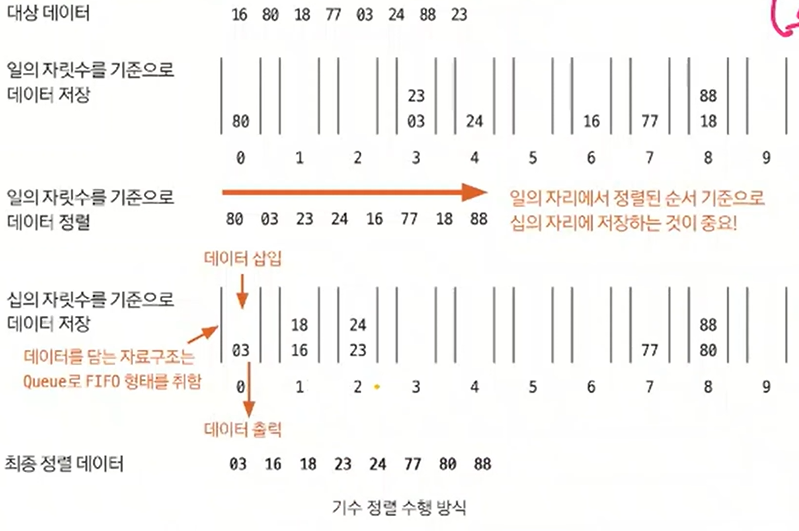
- 원본 배열 : 16 80 18 77 03 24 88 23
- 일의 자릿수 기준으로 배열 원소를 큐에 집어넣는다
- 이후 0번째 큐부터 9번째 큐까지 pop을 진행한다
- 그 결과 80 03 23 24 16 77 18 88이 만들어진다
- 이어서 십의 자릿수를 기준으로 같은 과정을 진행한다
- 마지막 자릿수를 기준으로 정렬할 때까지 앞의 과정을 반복한다
기수 정렬은 시간 복잡도가 가장 짧은 정렬이다. 만약 코딩테스트에서 정렬해야 하는 데이터의 개수가 너무 많으면 기수 정렬을 활용하자.
'Algorithm > [JAVA] Do it 알고리즘' 카테고리의 다른 글
| 자료구조 (Data Structure) (0) | 2023.08.12 |
|---|




