[ STACK BUFFER OVERFLOW ]
Calling Convention
▶ 함수 호출 규약
: 함수의 호출 및 반환에 대한 약속
한 함수에서 다른 함수를 호출할 때, 프로그램의 실행 흐름은 다른 함수로 이동하고 호출한 함수가 반환하면, 다시 원래의 함수로 돌아와서 기존의 실행 흐름을 이어나간다. 그러므로 함수를 호출할 때는 반환된 이후를 위해 호출자(Caller)의 상태(Stack frame) 및 반환 주소(Return Address)를 저장해야 한다. 또한, 호출자는 피호출자(Callee)가 요구하는 인자를 전달해줘야 하며, 피호출자의 실행이 종료될 때는 반환 값을 전달받아야 한다.
컴파일러의 도움 없이 어셈블리 코드를 작성하려 하거나, 또는 어셈블리로 작성된 코드를 읽고자 한다면 함수 호출 규약을 알아야 한다.
▶ 함수 호출 규약 종류
컴파일러는 지원하는 호출 규약 중, CPU 아키텍처에 적합한 것을 선택한다.
ex 1) x86(32bit) 아키텍처는 레지스터를 통해 피호출자의 인자를 전달하기에는 레지스터의 수가 적으므로, 스택으로 인자를 전달하는 규약을 사용
ex2 ) x86-64 아키텍처에서는 레지스터가 많으므로 적은 수의 인자는 레지스터만 사용해서 인자를 전달하고, 인자가 너무 많을 때만 스택을 사용
CPU의 아키텍처가 같아도, 컴파일러가 다르면 적용하는 호출 규약이 다를 수 있다. C언어를 컴파일할 때, 윈도우에서는 MSVC를, 리눅스에서는 gcc를 많이 사용한다. 이 둘은 같은 아키텍처에 대해서도 다른 호출 규약을 적용한다. x86-64 아키텍처에서 MSVC는 MS x64 호출 규약을 적용하지만, gcc는 SYSTEM V 호출 규약을 적용한다. 이 외에 같은 호출 규약을 컴파일러마다 다르게 구현하기도 한다.

x86호출 규약: cdecl
▶ cdecl
x86아키텍처는 레지스터의 수가 적으므로, 스택을 통해 인자를 전달한다. 또한, 인자를 전달하기 위해 사용한 스택을 호출자가 정리하는 특징이 있다. 스택을 통해 인자를 전달할 때는, 마지막 인자부터 첫 번째 인자까지 거꾸로 스택에 push한다.
- cdecl 함수 호출 규약
void __attribute__((cdecl)) callee(int a1, int a2){ // cdecl로 호출
}
void caller(){
callee(1, 2);
}위 코드를 어셈블리어로 컴파일한 결과

※ 컴파일
: 어떤 언어로 작성된 소스 코드(Source Code)를, 다른 언어의 목적 코드(Object Code)로 번역하는 것
소스 코드를 어셈블리어로, 또는 소스 코드를 기계어로 번역하는 행위 모두 컴파일의 범주에 포함된다.
C언어를 실행 가능한 바이너리로 만드는 과정을 보통 전처리, 컴파일, 어셈블, 링크의 4단계로 구분하는데, 이를 합해서 ‘컴파일’이라고 부를 수 있는 것도 위와 같은 이유이다.
x86-64호출 규약: SYSV
▶ SYSV
리눅스는 SYSTEM V(SYSV) Application Binary Interface(ABI)를 기반으로 만들어졌다.
SYSV ABI는 ELF 포맷, 링킹 방법, 함수 호출 규약 등의 내용을 담고 있다.

< SYSV에서 정의한 함수 호출 규약 >
- 6개의 인자를 RDI, RSI, RDX, RCX, R8, R9에 순서대로 저장하여 전달합니다. 더 많은 인자를 사용해야 할 때는 스택을 추가로 이용합니다.
- Caller에서 인자 전달에 사용된 스택을 정리합니다.
- 함수의 반환 값은 RAX로 전달합니다.
// Name: sysv.c
// Compile: gcc -fno-asynchronous-unwind-tables -masm=intel \
// -fno-omit-frame-pointer -S sysv.c -fno-pic -O0
#define ull unsigned long long
int callee(ull a1, int a2, int a3, int a4, int a5, int a6, int a7) {
ull ret = a1 + a2 + a3 + a4 + a5 + a6 + a7;
return ret;
}
void caller() { callee(123456789123456789, 2, 3, 4, 5, 6, 7); }
int main() { caller(); }▶ SYSV
1. 인자 전달

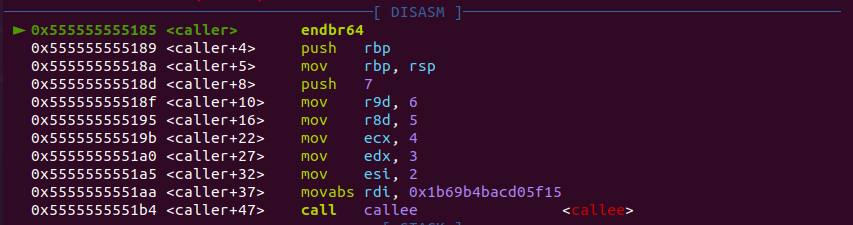
gdb로 sysv를 로드한 후 중단점을 설정하여 caller함수까지 실행한다. context의 DISASM을 보면, caller+6부터 caller+33까지 6개의 인자를 각각의 레지스터에 설정하고 있으며, caller+4에서는 7번째 인자인 7을 스택으로 전달하고 있다.


소스 코드에서 callee(123456789123456789, 2, 3, 4, 5, 6, 7)로 함수를 호출했는데, 인자들이 순서대로 rdi, rsi, rdx, rcx, r8, r9 그리고 [rsp]에 설정되어 있는 것을 확인할 수 있다.
2. 반환 주소 저장
si명령어로 한 단계 더 실행시킨다. call 이 실행되고 스택을 확인해보면 0x5555555551b9가 반환 주소로 저장되어 있다. gdb로 확인해보면 0x5555555551b9는 callee호출 다음 명령어의 주소이다. callee에서 반환됐을 때, 이 주소를 꺼내어 원래의 실행 흐름으로 돌아갈 수 있다.



3. 스택 프레임 저장
x/5i $rip명령어로 callee함수의 도입부(Prologue)를 살펴보면, 가장 먼저 push rbp를 통해 호출자의 rbp를 저장하고 있다. rbp가 스택프레임의 가장 낮은 주소를 가리키는 포인터이므로, 이를 Stack Frame Pointer(SFP)라고도 부른다.
callee에서 반환될 때, SFP를 꺼내어 caller의 스택 프레임으로 돌아갈 수 있다.
si로 push rbp를 실행하고, 스택을 확인해보면 rbp값인 0x00007fffffffdf98이 저장된 것을 확인할 수 있다.

4. 스택 프레임 할당
mov rbp, rsp로 rbp와 rsp가 같은 주소를 가리키게 한다. 바로 다음에 rsp의 값을 빼게 되면, rbp와 rsp의 사이 공간을 새로운 스택 프레임으로 할당하는 것이지만, callee 함수는 지역 변수를 사용하지 않으므로, 새로운 스택 프레임을 만들지 않는다.
si로 실행하고, 레지스터를 보면 이 둘이 같은 주소를 가리키는 것을 확인할 수 있다.


5. 반환값 전달
덧셈 연산을 모두 마치고, 함수의 종결부(Epilogue)에 도달하면, 반환값을 rax에 옮긴다. 반환 직전에 rax를 출력하면 전달한 7개 인자의 합인 123456789123456816을 확인할 수 있다.


6. 반환
반환은 저장해뒀던 스택 프레임과 반환 주소를 꺼내면서 이루어진다. 여기서는 callee 함수가 스택 프레임을 만들지 않았기 때문에, pop rbp로 스택 프레임을 꺼낼 수 있지만, 일반적으로 leave로 스택 프레임을 꺼낸다.
스택 프레임을 꺼낸 뒤에는, ret로 호출자로 복귀한다. 앞에서 저장해뒀던 sfp로 rbp가, 반환 주소로 rip가 설정된 것을 확인할 수 있다.


▶ 요약
[ Memory Corruption: Stack Buffer Overflow ]
스택 버퍼 오버플로우
▶ 버퍼 오버플로우
스택 오버플로우 : 스택 영역이 너무 많이 확장돼서 발생하는 버그
스택 버퍼 오버플로우 : 스택에 위치한 버퍼에 버퍼의 크기보다 많은 데이터가 입력되어 발생하는 버그
- 버퍼
: 데이터가 목적지로 이동되기 전에 보관되는 임시 저장소
데이터의 처리속도가 다른 두 장치가 있을 때, 이 둘 사이에 오가는 데이터를 임시로 저장해 두는 것은 일종의 완충 작용을 한다. 버퍼를 통해 간접적으로 데이터를 전달하게 한다. 송신 측은 버퍼로 데이터를 전송하고, 수신 측은 버퍼에서 데이터를 꺼내 사용한다. 이렇게 하면 버퍼가 가득 찰 때까지는 유실되는 데이터 없이 통신할 수 있니다. 빠른 속도로 이동하던 데이터가 안정적으로 목적지에 도달할 수 있도록 완충 작용을 하는 것이 버퍼의 역할이라고 할 수 있다.
현대에는 이런 완충의 의미가 많이 희석되어 데이터가 저장될 수 있는 모든 단위를 버퍼라고 부른다.
스택 버퍼 : 스택에 있는 지역 변수
힙 버퍼 : 힙에 할당된 메모리 영역
- 버퍼 오버플로우
: 버퍼가 넘치는 것
버퍼는 제각기 크기를 가지고 있는데, int로 선언한 지역 변수는 4바이트의 크기를 갖고, 10개의 원소를 갖는 char배열은 10바이트의 크기를 갖는다. 만약 10바이트 크기의 버퍼에 20바이트 크기의 데이터가 들어가려 하면 오버플로우가 발생한다. 일반적으로 버퍼는 메모리상에 연속해서 할당되어 있으므로, 어떤 버퍼에서 오버플로우가 발생하면, 뒤에 있는 버퍼들의 값이 조작될 위험이 있다
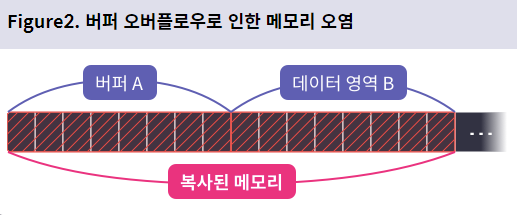
버퍼 오버플로우는 일반적으로 어떤 메모리 영역에서 발생해도 큰 보안 위협으로 이어진다.
▶ 중요 데이터 변조
버퍼 오버플로우가 발생하는 버퍼 뒤에 중요한 데이터가 있다면, 해당 데이터가 변조됨으로써 문제가 발생할 수 있다.
ex) 입력 데이터에서 악성 데이터를 감지하여 경고해주는 프로그램이 있을 때, 악성의 조건이 변경되면 악성 데이터에도 알람이 울리지 않을 수 있다.
// Name: sbof_auth.c
// Compile: gcc -o sbof_auth sbof_auth.c -fno-stack-protector
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int check_auth(char *password) {
int auth = 0;
char temp[16];
strncpy(temp, password, strlen(password));
if(!strcmp(temp, "SECRET_PASSWORD"))
auth = 1;
return auth;
}
int main(int argc, char *argv[]) {
if (argc != 2) {
printf("Usage: ./sbof_auth ADMIN_PASSWORD\n");
exit(-1);
}
if (check_auth(argv[1]))
printf("Hello Admin!\n");
else
printf("Access Denied!\n");
}main 함수는 argv[1]을 check_auth 함수의 인자로 전달한 후, 반환 값을 받아온다. 이 때, 반환 값이 0이 아니라면 "Hello Admin!"을, 0이라면 "Access Denied!"라는 문자열을 출력한다.
check_auth함수에서는 16 바이트 크기의 temp버퍼에 입력받은 패스워드를 복사한 후, 이를 "SECRET_PASSWORD" 문자열과 비교한다. 문자열이 같다면 auth를 1로 설정하고 반환한다.
그런데 check_auth에서 strncpy 함수를 통해 temp버퍼를 복사할 때, temp의 크기인 16 바이트가 아닌 인자로 전달된 password의 크기만큼 복사한다. 그러므로 argv[1]에 16 바이트가 넘는 문자열을 전달하면, 이들이 모두 복사되어 스택 버퍼 오버플로우가 발생하게 된다.
auth는 temp버퍼의 뒤에 존재하므로, temp버퍼에 오버플로우를 발생시키면 auth의 값을 0이 아닌 임의의 값으로 바꿀 수 있다. 이 경우, 실제 인증 여부와는 상관없이 main함수의 if(check_auth(argv[1])) 는 항상 참이 된다.
- SECRET_PASSWORD 문자열과 동일할 때
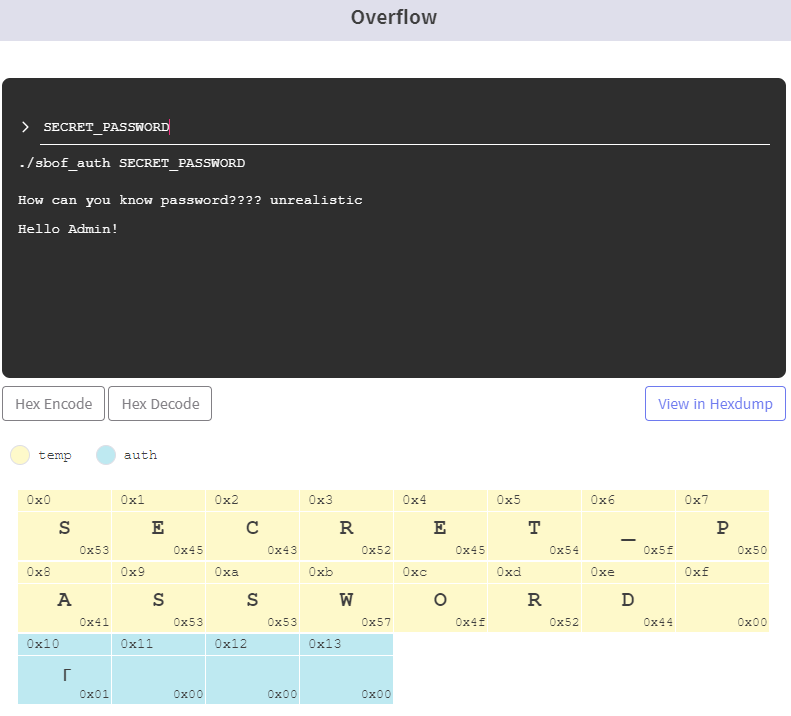
- SECRET_PASSWORD 문자열과 동일하지 않을 때

- temp버퍼에 오버플로우를 발생시킬 때

temp버퍼에 오버플로우를 발생시키면 auth의 값을 0이 아닌 임의의 값으로 바꿀 수 있어 인증이 안되었지만 main함수의 if(check_auth(argv[1])) 가 참이 되었다.
▶ 데이터 유출
C언어에서 정상적인 문자열은 널바이트로 종결되며, 표준 문자열 출력 함수들은 널바이트를 문자열의 끝으로 인식한다. 만약 어떤 버퍼에 오버플로우를 발생시켜서 다른 버퍼와의 사이에 있는 널바이트를 모두 제거하면, 해당 버퍼를 출력시켜서 다른 버퍼의 데이터를 읽을 수 있다. 획득한 데이터는 각종 보호기법을 우회하는데 사용될 수 있으며, 해당 데이터 자체가 중요한 정보일 수도 있다.
// Name: sbof_leak.c
// Compile: gcc -o sbof_leak sbof_leak.c -fno-stack-protector
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main(void) {
char secret[16] = "secret message";
char barrier[4] = {};
char name[8] = {};
memset(barrier, 0, 4);
printf("Your name: ");
read(0, name, 12);
printf("Your name is %s.", name);
}8바이트 크기의 name 버퍼에 12바이트의 입력을 받는다. 읽고자 하는 데이터인 secret버퍼와의 사이에 barrier라는 4바이트의 널 배열이 존재하는데, 오버플로우를 이용하여 널 바이트를 모두 다른 값으로 변경하면 secret을 읽을 수 있다.

name버퍼에 abcdefghijkl로 총 12바이트의 입력을 해주었다. 원래 name 버퍼 크기는 8바이트이므로 오버플로우가 되었고 이 때문에 뒤에 secret message가 추가적으로 붙은 것을 확인할 수 있다.
▶ 실행 흐름 조작
함수를 호출할 때 반환 주소를 스택에 쌓고, 함수에서 반환될 때 이를 꺼내어 원래의 실행 흐름으로 돌아간다 .이를 공격자의 관점에서 바라보면, '스택 버퍼 오버플로우로 반환 주소(Return Address)를 조작하면 어떻게 될까'하는 궁금증을 가져볼 수 있다. 그리고 실제로, 함수의 반환 주소를 조작하면 프로세스의 실행 흐름을 바꿀 수 있다.
// Name: sbof_ret_overwrite.c
// Compile: gcc -o sbof_ret_overwrite sbof_ret_overwrite.c -fno-stack-protector
#include <stdio.h>
#include <stdlib.h>
int main(void) {
char buf[8];
printf("Overwrite return address with 0x4141414141414141: ");
gets(buf);
return 0;
}

'SYSTEM Hacking' 카테고리의 다른 글
| [SISS] Dreamhack System Hacking (STAGE 5) (0) | 2022.01.26 |
|---|---|
| [SISS] Dreamhack System Hacking (STAGE 4) - 실습 (0) | 2022.01.22 |
| [SISS] Dreamhack System Hacking (STAGE 3) (0) | 2022.01.21 |
| [SISS] Dreamhack System Hacking (STAGE 2) - 실습 (0) | 2022.01.21 |
| [SISS] Dreamhack System Hacking (STAGE 2) (0) | 2022.01.10 |













































































